Alors que nous venons juste de publier un article sur le robot quadrupède de la société Unitree et son modèle GO2, l’Institut coréen de science et technologie avancées ( KAIST ) a annoncé de son côté le développement d’une technologie permettant à un robot du même acabit de se déplacer avec une agilité impressionnante, même sur des terrains mous tels qu’une plage.
Cette technologie a été conçue par une équipe de recherche dirigée par le professeur Jemin Hwangbo du département de génie mécanique.
Le professeur Hwangbo et son équipe ont mis au point une technologie permettant de modéliser la force reçue par un robot marcheur sur un sol composé de matériaux granulaires, comme le sable. Ils ont ensuite simulé ce mouvement sur un robot quadrupède.
Par ailleurs, l’équipe a travaillé sur une structure de réseau neuronal artificiel, essentielle pour prendre des décisions en temps réel, comme s’adapter à différents types de sol tout en marchant, sans informations préalables.
Cette nouvelle approche, appliquée à l’apprentissage par renforcement, promet d’élargir le champ d’application des robots marcheurs quadrupèdes. En effet, le réseau de neurones entraîné démontre sa robustesse en terrains changeants, notamment la capacité de se déplacer à haute vitesse sur une plage de sable ou de marcher et de tourner sur des sols mous, comme un matelas gonflable, sans perdre l’équilibre.

Un contrôleur apprenant de l’environnement
L’apprentissage par renforcement est une méthode d’apprentissage de l’intelligence artificielle. Elle sert à créer une machine qui collecte des données sur les résultats de diverses actions dans une situation donnée et utilise ces données pour accomplir une tâche. Les simulations permettant d’approximer les phénomènes physiques de l’environnement réel sont largement utilisées pour la collecte de données nécessaire à cet apprentissage.
Le défi dans le cas des robots marcheurs est d’appliquer ces contrôleurs basés sur l’apprentissage à des environnements réels, après un apprentissage effectué à partir de données collectées en simulation, pour réussir à contrôler la marche dans divers terrains.
Une simulation efficace du terrain
Les chercheurs ont défini un modèle de contact prédisant la force générée lors du contact avec le sol en fonction des dynamiques de mouvement du robot, à partir d’un modèle de force de réaction au sol qui prend en compte l’effet de la masse supplémentaire des médias granulaires. En calculant la force générée à chaque pas, l’équipe a réussi à simuler efficacement le comportement du robot sur un terrain déformable.
De plus, l’équipe a introduit une structure de réseau neuronal artificiel capable de prédire implicitement les caractéristiques du sol en utilisant un réseau neuronal récurrent qui analyse les données temporelles provenant des capteurs du robot.

Performances impressionnantes du robot ‘RaiBo’
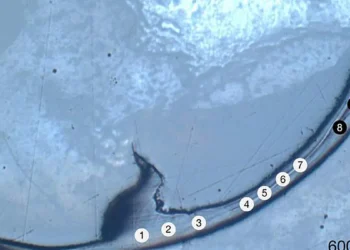
Le contrôleur appris a été monté sur le robot ‘RaiBo’, conçu par l’équipe de recherche. Le robot a montré des performances élevées, comme une marche à haute vitesse (jusqu’à 3,03 m/s) sur une plage de sable, les pieds complètement enfouis dans le sable. Il s’est aussi montré stable et adaptable à diverses surfaces, comme les champs herbeux ou une piste d’athlétisme, sans aucune programmation ou révision supplémentaire de l’algorithme de contrôle.
Il a également pu effectuer des rotations stables à 1,54 rad/s (environ 90° par seconde) sur un matelas gonflable, démontrant une adaptation rapide même lorsque le terrain devient soudainement mou.
En synthèse
La méthodologie de simulation et d’apprentissage développée par l’équipe de recherche du KAIST ouvre de nouvelles perspectives pour les robots accomplissant des tâches pratiques, en élargissant la gamme de terrains sur lesquels différents robots marcheurs peuvent opérer. La clé de cette innovation réside dans l’expérience de contact proche de la réalité offerte au contrôleur basé sur l’apprentissage, qui se révèle essentielle pour une application sur des terrains déformables.
Le doctorant Soo-Young Choi, premier auteur de cette recherche, a indiqué : « Il a été démontré que fournir à un contrôleur basé sur l’apprentissage une expérience de contact proche avec un sol réellement déformable est essentiel pour une application à un terrain déformable. » Il a ajouté : « Le contrôleur proposé peut être utilisé sans information préalable sur le terrain, il peut donc être appliqué à diverses études sur la marche des robots.«