Fondée sur le principe du rasoir d’Occam « Le plus simple est le mieux », une équipe de chercheurs de KAUST a développé un package statistique qui ajuste de manière optimale les modèles statistiques flexibles pour les données spatio-temporelles.
Cette approche, implémentée dans des logiciels de statistiques largement utilisés, aidera les chercheurs à faire des prédictions plus précises à partir de données d’observation.
Les méthodes statistiques sont les principaux outils utilisés par les chercheurs pour donner un sens aux données d’observation. Certains jeux de données ont des représentations statistiques simples, comme la distribution des tailles dans une population, avec une moyenne et une distribution à peu près égale de valeurs plus élevées et plus basses. Cependant, de nombreux phénomènes environnementaux ne suivent pas de telles distributions « gaussiennes » simples et nécessitent des interprétations statistiques plus flexibles.
Une distribution non gaussienne avec une forme différente peut être dérivée en entraînant un modèle pour l’ajuster aux données observées à l’aide de diverses méthodes statistiques. Cependant, seule, cette approche peut conduire à des résultats étranges qui s’éloignent des phénomènes sous-jacents.
« Les modèles non gaussiens entraînés ont tendance à ‘surajuster’ trop facilement les données, en particulier lorsque la taille des données n’est pas importante« , explique Rafael Cabral, statisticien ayant fait son doctorat à KAUST. « En s’entraînant trop bien sur les données observées, cette approche peut capturer des fluctuations aléatoires plutôt que le motif sous-jacent.«
Cette situation peut se produire lorsqu’un modèle a trop de flexibilité par rapport aux données disponibles, et tend donc vers des modèles non gaussiens plus complexes alors qu’un modèle gaussien plus simple pourrait en fait être le meilleur choix. Le statisticien, avec David Bolin et Håvard Rue, a conçu un cadre pour garder ce processus d’entraînement sous contrôle.
« Pour y remédier, nous avons utilisé l’apprentissage bayésien, qui nous permet d’incorporer des connaissances et des croyances a priori sur les données dans notre modèle de manière rigoureuse et quantifiée« , explique Rafael Cabral. « Le résultat est alors un compromis entre les preuves fournies par les données et nos croyances a priori, ce qui pénalise la complexité du modèle et donne la préférence au modèle gaussien plus simple conformément au principe du rasoir d’Occam« .
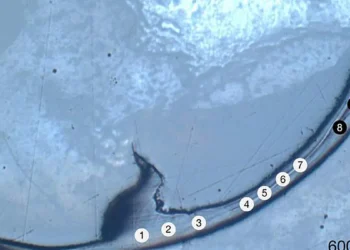
L’équipe de recherche a démontré l’utilité de leur approche en l’appliquant à des données spatiales de température et de pression, obtenant un modèle non gaussien avec de meilleures prédictions que les autres approches en contrôlant la flexibilité du modèle.
Fait important, l’équipe a implémenté leur modèle dans des logiciels statistiques standard pour fournir un contrôle automatisé de l’application de modèles statistiques flexibles.
« Cette mise en œuvre fournit aux chercheurs une méthode pour appliquer des modèles non gaussiens à des données réelles, avec l’avantage qu’elle est efficace sur le plan informatique et assez automatique à utiliser dans les logiciels« , conclut David Bolin, qui dirige le groupe des processus stochastiques et de la statistique appliquée de KAUST.
Les codes statistiques sont disponibles publiquement pour R-INLA et Stan via Github (stan-dev/connect22-space-time).
Légende illustration principale : En utilisant des données spatiales de température et de pression, les chercheurs de KAUST ont démontré l’utilité de leur nouvelle approche pour obtenir un modèle non gaussien avec de meilleures prédictions que les autres approches. Image générée par l’IA à l’aide du générateur d’images Microsoft Bing.
Cabral, R., Bolin, D and Rue, H. Controlling the flexibility of non-Gaussian processes through shrinkage priors. Bayesian Analysis (2022).| article
Article traduit de l’auteur : Rafael Medeiros Cabral