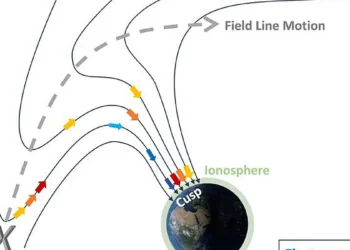
Parmi les principales préoccupations entourant l’intelligence artificielle, on trouve sa tendance à fournir des informations erronées lors du résumé de longs documents. Ces « hallucinations » sont problématiques non seulement parce qu’elles véhiculent des faussetés, mais aussi parce qu’elles réduisent l’efficacité – trier le contenu pour rechercher les erreurs des sorties d’IA est chronophage.
Pour aider à relever ce défi, une équipe d’informaticiens a créé un cadre algorithmique qui s’inspire d’un phénomène naturel – le vol des oiseaux – en mimant la façon dont les oiseaux s’auto-organisent efficacement. Ce cadre sert d’étape de prétraitement pour les grands modèles de langage (LLM), les aidant à produire des résumés plus fiables de grands documents.
Les chercheurs ont créé l’algorithme de vol d’oiseaux en commençant par analyser comment les agents IA font des erreurs.
Ces systèmes sont construits sur des LLM conçus pour rechercher, écrire et résumer de manière autonome. Mais même s’ils écrivent bien, ils ne produisent pas toujours des résumés exacts ou fidèles.
« Un facteur contributif est que lorsque le texte d’entrée est excessivement long, bruyant ou répétitif, les performances du modèle se dégradent, ce qui amène les agents IA et les LLM à perdre la trace des faits clés, à diluer les informations critiques parmi un contenu non pertinent, ou à s’éloigner complètement du matériel source », explique Anasse Bari, professeur d’informatique au Courant Institute School of Mathematics, Computing, and Data Science de NYU et directeur du Predictive Analytics and AI Research Lab, qui a mené ce travail.
S’inspirant de la cause de cette lacune, Bari et son co-auteur Binxu Huang, chercheur en informatique à NYU, se sont tournés vers une méthode ordonnée et éprouvée pour rassembler des parties disparates – le vol des oiseaux – et l’ont appliquée comme étape de prétraitement à l’IA générative.
Leur méthode considérait chaque phrase d’un long document – une étude scientifique ou une analyse juridique – comme un oiseau virtuel. Pour produire un résultat simplifié, elle évaluait les phrases du document en fonction de leur position, de leur centralité thématique et de leur pertinence topique, puis les regroupait en clusters qui reflètent la façon dont les oiseaux s’auto-organisent en volées.
Ce regroupement réduisait chaque cluster à ses phrases les plus représentatives, dans le but de minimiser la redondance et de préserver les points clés. Le résumé trié qui en résultait était ensuite transmis à un LLM comme entrée structurée, concise et réduite.
« L’intention était d’ancrer les modèles d’IA plus près du matériel source tout en réduisant la répétition et le bruit avant de générer un résumé final », explique Bari, qui s’est précédemment tourné vers des phénomènes naturels pour concevoir un algorithme pour améliorer les recherches en ligne.
Voici comment cela fonctionne plus en détail :
Phase 1 : Noter chaque phrase
Chaque phrase est nettoyée en ne gardant que les noms, verbes et adjectifs, tout en supprimant les articles, prépositions, conjonctions et ponctuation. Parmi d’autres techniques de traitement du langage naturel, les termes composés de plusieurs mots sont également fusionnés (« cancer du poumon » devient « cancer_du_poumon ») pour que les concepts uniques restent intacts.
Chaque phrase est ensuite convertie en un vecteur numérique en fusionnant des caractéristiques lexicales, sémantiques et topiques. Les phrases sont notées sur la centralité à l’échelle du document, l’importance au niveau de la section et l’alignement avec le résumé, avec un boost numérique pour les sections clés comme l’introduction, les résultats et la conclusion.
Phase 2 : Vol d’oiseaux pour la diversité
Ne prendre que les phrases les mieux notées risquerait la répétition – et entraverait le vol. Par exemple, dans un article de recherche sur le cancer, les cinq phrases les mieux classées pourraient toutes discuter des résultats des traitements. Au lieu de cela, le cadre traite chaque phrase comme un oiseau positionné dans un espace imaginaire selon son sens. Tout comme les vrais oiseaux dans la nature, qui s’auto-organisent en volées en suivant trois règles simples connues sous le nom de cohésion (rester près des oiseaux voisins), alignement (se déplacer dans la même direction que les voisins) et séparation (éviter l’entassement), les phrases ayant des significations similaires se regroupent naturellement tout en maintenir des groupes distincts. Des leaders émergent au sein de chaque cluster et les suiveurs s’attachent à leur leader le plus proche.
À partir de chaque volée finale de phrases similaires, seules celles ayant le score le plus élevé sont sélectionnées, de sorte que le résumé couvre le contexte, les méthodes, les résultats et les conclusions, plutôt que de répéter un seul thème – reflétant ainsi la diversité de contenu d’un document sans le répéter. Les phrases choisies sont réordonnées et transmises à un agent IA alimenté par un LLM, qui les synthétise en un résumé fluide ancré dans le contenu source original.
Les chercheurs ont évalué l’algorithme sur plus de 9 000 documents, examinant si cette approche produisait de meilleurs résultats par rapport à un agent IA alimenté uniquement par un LLM. Le cadre, y compris son algorithme inspiré du vol d’oiseaux, combiné aux LLM, a aidé à générer des résumés avec une plus grande exactitude factuelle que les LLM produisant du contenu sans l’algorithme.
« L’idée centrale de notre travail est que nous avons développé un cadre expérimental qui sert d’étape de prétraitement pour les grands textes avant qu’ils ne soient donnés à un agent IA ou à un LLM, et non comme un concurrent des LLM ou des agents IA », explique Bari. « Le cadre identifie les phrases les plus importantes d’un document et crée une représentation et un résumé plus concis du texte original, supprimant la répétition et le bruit avant qu’il n’atteigne l’IA. »
Cependant, les auteurs reconnaissent que leur approche n’est pas une panacée.
« Le but est d’aider l’IA à générer des résumés qui restent plus près du matériel source », note Bari. « Bien que cette approche ait le potentiel de résoudre partiellement le problème de l’hallucination, nous ne voulons pas prétendre que nous l’avons résolu – nous ne l’avons pas fait. »
Article : A Bird-Inspired Artificial Intelligence Framework for Advanced Large Text Summarization – Journal : Frontiers in Artificial Intelligence – Méthode : Data/statistical analysis – DOI : Lien vers l’étude
Source : NYU
Newsletter Enerzine
Recevez les meilleurs articles
Énergie, environnement, innovation, science : l’essentiel directement dans votre boîte mail.